
Punto único de fallo
Bajo un solo punto de falla ( SPOF corto o único punto de falla alemán ) se define como una parte de un sistema técnico cuya falla provoca la falla de todo el sistema por sí mismo.
En el caso de sistemas de alta disponibilidad , debe asegurarse que todos los componentes de un sistema estén diseñados de forma redundante . La diversidad también debería influir. Se utilizan sistemas de diferentes estructuras (por ejemplo, diferentes fabricantes) para la misma tarea. Esto hace que sea menos probable una falla simultánea de varios sistemas por una sola razón.
principio
Dependiendo de los requisitos, es posible que los dispositivos redundantes no funcionen en la misma ubicación; de lo contrario, todavía existe un SPOF:
- En el accidente de Fukushima , los generadores de energía de emergencia con motor diésel estuvieron presentes varias veces, lo que constituye una salvaguardia suficiente en muchos escenarios de daños. Sin embargo, el tsunami destruyó gran parte de los generadores de emergencia. Desde entonces, se han implementado dispositivos móviles de energía de emergencia y los ubicados en una colina a salvo de inundaciones.
- El mismo problema surge con la copia de seguridad de los datos : si se realiza una copia de seguridad de los datos en un disco duro externo y se almacena en su propia oficina, esto es ciertamente suficiente en los escenarios " laptop destruida por café servido" y "ladrón roba la computadora portátil", pero ya no cuando un incendio destruye toda la oficina. En tal caso, el disco duro debería almacenarse en una caja de seguridad , por ejemplo , para garantizar la redundancia.
En el sector de las TI
Como paso sencillo para evitar múltiples SPOF en las operaciones de TI, se pueden utilizar varias fuentes de alimentación ininterrumpida (UPS) , se pueden diseñar partes del servidor de forma redundante (unidades de alimentación y tarjetas de red) y se puede aumentar suficientemente el número de dispositivos finales utilizados .
Al conectarse a múltiples transformadores del proveedor de energía , integrando cableado cruzado (múltiples rutas de corriente), uno o más generadores como sistema de energía de emergencia , sistemas de TI con múltiples fuentes de alimentación o usando múltiples STS (balastos), aire acondicionado redundante y múltiples accesos a Los dispositivos finales la propia red de la empresa (CorporateNetwork) proporciona una infraestructura que está protegida en gran medida contra fallas. El siguiente aumento en la disponibilidad se logra mediante el uso de sistemas de clúster o servidores internamente altamente redundantes ( tolerantes a fallas ) . Además, los centros de datos de respaldo se pueden utilizar en caso de desastre.
- ejemplo
En una empresa, la red informática debe estar protegida contra fallas de energía y del servidor. "SPOF" significa un solo elemento, cuya falla afecta a todo el sistema.
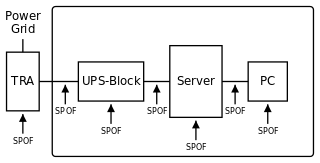
Posibles puntos de falla en una operación no asegurada. Además de otros puntos débiles: en caso de un corte de energía, el sistema de alimentación ininterrumpida (UPS) se activa; sin embargo, la conexión entre el UPS y la computadora no está protegida contra fallas. Asimismo, no hay una segunda computadora (PC) disponible, en caso de que presente fallas.

Primera reducción de puntos de interrupción para una operación de TI. Se han eliminado algunos SPOF. Sin embargo, los datos solo se pueden intercambiar a través de un servidor. En caso de un corte de energía, solo puede trabajar mientras los dos bloques de UPS estén suministrando energía
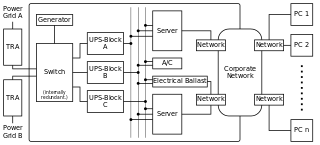
Fuente de alimentación redundante y con cable cruzado en el centro de datos. La operación está muy bien asegurada contra fallas de una red eléctrica, el servidor y las conexiones eléctricas / electrónicas.



Aviación
En la aviación se trata de evitar puntos únicos de avería de suma importancia. Sin embargo, si una falla no afecta la seguridad, o si los análisis de seguridad confirman que la falla ocurre con bastante poca frecuencia, se permite un solo punto de falla.
La FAA divide los sistemas a bordo, debido a sus posibles fallas de funcionamiento, en las siguientes categorías:
- Falla menor (puede ocurrir más de 1 por cada 100,000 horas de funcionamiento, no tiene impacto en la seguridad)
- Falla mayor (debe ocurrir menos de una vez cada 100,000 horas, todos los ocupantes sobreviven al incidente)
- Falla peligrosa (debe ocurrir menos de una vez por cada 10 millones de horas de operación, requiere habilidades de alto vuelo, algunos ocupantes mueren en el incidente)
- Falla catastrófica (debe ocurrir menos de una vez por mil millones de horas de operación, la aeronave se pierde irremediablemente incluso con los mejores pilotos, la mayoría de los pasajeros mueren en el incidente)
Si una falla del sistema significa una falla mayor , se permite un diseño único que no sea a prueba de fallas. Por el contrario, la falla de un solo sistema no debería resultar en una falla catastrófica .
- Dispositivos de medición y aviónica
Un avión moderno procesa continuamente docenas de diferentes valores medidos: altitud , velocidad, valores de posición del sistema de navegación inercial , datos del motor, la recepción de señales del sistema de aterrizaje por instrumentos y muchos más.
Dependiendo de los requisitos, estos datos no solo deben recopilarse de manera segura, sino que también deben procesarse de manera segura. En los aviones modernos se utilizan tres ordenadores de control de vuelo independientes, que obtienen los datos brutos de tres fuentes independientes ( tubos pitot , sondas estáticas ...).
Suponiendo que el mal funcionamiento dual de un sistema es extremadamente improbable, un sistema triple puede detectar la lectura correcta y descartar la incorrecta. Si solo hay dos sistemas activos, el sistema puede al menos notificar a los pilotos de un valor medido cuestionable, pero ya no puede decidir cuál de los dos valores es correcto.
- control
Los sistemas de control de un avión comercial fueron diseñados dos o incluso tres veces por razones de seguridad y al mismo tiempo ya no eran practicables a más tardar para los aviones más modernos de gran capacidad Boeing 747 , Lockheed Tristar o Douglas DC-10 en un de forma puramente mecánica mediante palancas, varillas o cables. Fueron reemplazados por sistemas hidráulicos y posteriormente eléctricos / electrónicos para transmitir los comandos de control a los accionamientos de las aletas (los llamados fly-by-wire ). Utilizando la transmisión de señales eléctricas, ahora era mucho más fácil garantizar la redundancia necesaria.
En el caso de la transmisión de señales hidráulicas, contra todo pronóstico, fue posible en casos individuales que los tres sistemas fueran dañados por el mismo incidente y fallaran debido a la proximidad de los sistemas redundantes. En el vuelo 232 de United Airlines, por ejemplo, las partes del motor astilladas de un DC-10 destruyeron los tres sistemas hidráulicos. En el vuelo 123 de Japan Air Lines , los cuatro sistemas de un Boeing 747 fueron destruidos después de una liberación de presión de la cabina presurizada.
El EBHA (actuador hidráulico de respaldo eléctrico) a bordo del Airbus 380 y Gulfstream 650 representa una mejora adicional . Normalmente, los actuadores operados hidráulicamente se controlan eléctrica / electrónicamente; la falla de las líneas hidráulicas aún apagaría dicho actuador. Una EBHA, por otro lado, tiene su propio sistema hidráulico autosuficiente. Los EBHA permiten ahorrar uno de los tres sistemas hidráulicos y, por lo tanto, el peso.
Evidencia individual
- ↑ Tadashi Narabayashi: Contramedidas derivadas de las lecciones del accidente de la planta de energía nuclear de Fukushima Daiichi. En: Actas de la 21ª Conferencia Internacional de Ingeniería Nuclear de 2013. Consultado el 17 de julio de 2019 .
- ↑ AC 25.1309-1A "Diseño y análisis de sistemas", FAA, ver AC 25.1309-1
- ↑ Informe de un testigo presencial: Vuelo 232 de United ( Memento del 18 de abril de 2001 en el Archivo de Internet )
- ↑ G650 vuela con actuadores hidráulicos de respaldo eléctrico. En: Aviación australiana. Consultado el 25 de abril de 2021 (inglés australiano).